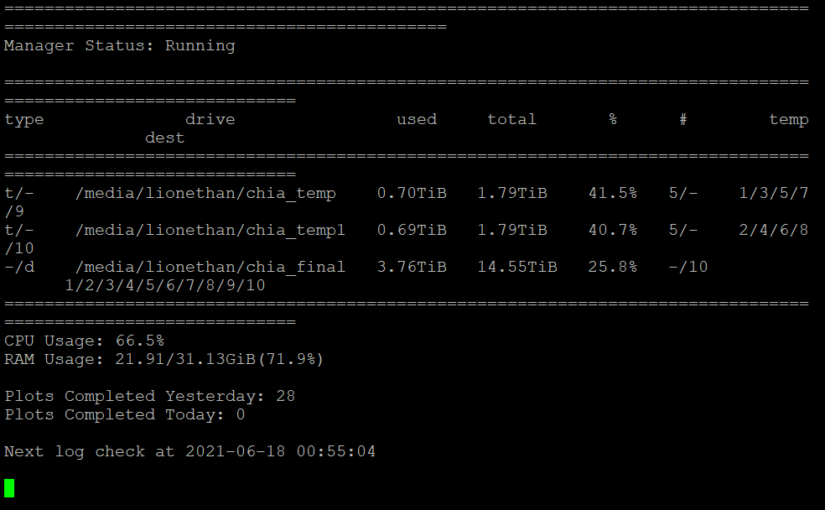
建議電腦配置:
處理器 i7-10700 or 11700
主機板 b460 / z490 / b560 / z590 (支援兩個以上的M.2插槽)
記憶體 16GB D4-3200 x 2
系統碟 SATA SSD 250GB
緩存碟 M.2 SSD PCIE4 2TB x 2 (其實1TB x 2就可以了)
BIOS配置:
Intel C-State設為Disabled
# This is a single variable that should contain the location of your chia executable file. This is the blockchain executable.
#
# WINDOWS EXAMPLE: C:\Users\Swar\AppData\Local\chia-blockchain\app-1.1.5\resources\app.asar.unpacked\daemon\chia.exe
# LINUX EXAMPLE: /usr/lib/chia-blockchain/resources/app.asar.unpacked/daemon/chia
# LINUX2 EXAMPLE: /home/swar/chia-blockchain/venv/bin/chia
# MAC OS EXAMPLE: /Applications/Chia.app/Contents/Resources/app.asar.unpacked/daemon/chia
chia_location: /home/lionethan/chia-blockchain/venv/bin/chia
manager:
# These are the config settings that will only be used by the plot manager.
#
# check_interval: The number of seconds to wait before checking to see if a new job should start.
# log_level: Keep this on ERROR to only record when there are errors. Change this to INFO in order to see more
# detailed logging. Warning: INFO will write a lot of information.
check_interval: 60
log_level: ERROR
log:
# folder_path: This is the folder where your log files for plots will be saved.
folder_path: /home/lionethan/.chia/mainnet/plotter
view:
# These are the settings that will be used by the view.
#
# check_interval: The number of seconds to wait before updating the view.
# datetime_format: The datetime format that you want displayed in the view. See here
# for formatting: https://docs.python.org/3/library/datetime.html#strftime-and-strptime-format-codes
# include_seconds_for_phase: This dictates whether seconds are included in the phase times.
# include_drive_info: This dictates whether the drive information will be showed.
# include_cpu: This dictates whether the CPU information will be showed.
# include_ram: This dictates whether the RAM information will be showed.
# include_plot_stats: This dictates whether the plot stats will be showed.
check_interval: 60
datetime_format: "%Y-%m-%d %H:%M:%S"
include_seconds_for_phase: false
include_drive_info: true
include_cpu: true
include_ram: true
include_plot_stats: true
notifications:
# These are different settings in order to notified when the plot manager starts and when a plot has been completed.
# DISCORD
notify_discord: true
discord_webhook_url: https://discordapp.com/api/webhooks/844138664589393920/io3jQxoTO6XoYOtbddojJkE-IXDSsWZ8wpIxTHgaFpdYvBgfRuHjbBYBMECgXl1em3uG
# IFTTT, ref https://ifttt.com/maker_webhooks, and this function will send title as value1 and message as value2.
notify_ifttt: false
ifttt_webhook_url: https://maker.ifttt.com/trigger/{event}/with/key/{api_key}
# PLAY AUDIO SOUND
notify_sound: false
song: audio.mp3
# PUSHOVER PUSH SERVICE
notify_pushover: false
pushover_user_key: xx
pushover_api_key: xx
# TELEGRAM
notify_telegram: false
telegram_token: xxxxx
# TWILIO
notify_twilio: false
twilio_account_sid: xxxxx
twilio_auth_token: xxxxx
twilio_from_phone: +1234657890
twilio_to_phone: +1234657890
instrumentation:
# This setting is here in case you wanted to enable instrumentation using Prometheus.
prometheus_enabled: false
prometheus_port: 9090
progress:
# phase_line_end: These are the settings that will be used to dictate when a phase ends in the progress bar. It is
# supposed to reflect the line at which the phase will end so the progress calculations can use that
# information with the existing log file to calculate a progress percent.
# phase_weight: These are the weight to assign to each phase in the progress calculations. Typically, Phase 1 and 3
# are the longest phases so they will hold more weight than the others.
phase1_line_end: 801
phase2_line_end: 834
phase3_line_end: 2474
phase4_line_end: 2620
phase1_weight: 33.4
phase2_weight: 20.43
phase3_weight: 42.29
phase4_weight: 3.88
global:
# These are the settings that will be used globally by the plot manager.
#
# max_concurrent: The maximum number of plots that your system can run. The manager will not kick off more than this
# number of plots total over time.
# max_for_phase_1: The maximum number of plots that your system can run in phase 1.
# minimum_minutes_between_jobs: The minimum number of minutes before starting a new plotting job, this prevents
# multiple jobs from starting at the exact same time. This will alleviate congestion
# on destination drive. Set to 0 to disable.
max_concurrent: 16
max_for_phase_1: 4
minimum_minutes_between_jobs: 5
jobs:
# These are the settings that will be used by each job. Please note you can have multiple jobs and each job should be
# in YAML format in order for it to be interpreted correctly. Almost all the values here will be passed into the
# Chia executable file.
#
# Check for more details on the Chia CLI here: https://github.com/Chia-Network/chia-blockchain/wiki/CLI-Commands-Reference
#
# name: This is the name that you want to give to the job.
# max_plots: This is the maximum number of jobs to make in one run of the manager. Any restarts to manager will reset
# this variable. It is only here to help with short term plotting.
#
# [OPTIONAL] farmer_public_key: Your farmer public key. If none is provided, it will not pass in this variable to the
# chia executable which results in your default keys being used. This is only needed if
# you have chia set up on a machine that does not have your credentials.
# [OPTIONAL] pool_public_key: Your pool public key. Same information as the above.
#
# temporary_directory: Can be a single value or a list of values. This is where the plotting will take place. If you
# provide a list, it will cycle through each drive one by one.
# [OPTIONAL] temporary2_directory: Can be a single value or a list of values. This is an optional parameter to use in
# case you want to use the temporary2 directory functionality of Chia plotting.
# destination_directory: Can be a single value or a list of values. This is the final directory where the plot will be
# transferred once it is completed. If you provide a list, it will cycle through each drive
# one by one.
#
# size: This refers to the k size of the plot. You would type in something like 32, 33, 34, 35... in here.
# bitfield: This refers to whether you want to use bitfield or not in your plotting. Typically, you want to keep
# this as true.
# threads: This is the number of threads that will be assigned to the plotter. Only phase 1 uses more than 1 thread.
# buckets: The number of buckets to use. The default provided by Chia is 128.
# memory_buffer: The amount of memory you want to allocate to the process.
# max_concurrent: The maximum number of plots to have for this job at any given time.
# max_concurrent_with_start_early: The maximum number of plots to have for this job at any given time including
# phases that started early.
# initial_delay_minutes: This is the initial delay that is used when initiate the first job. It is only ever
# considered once. If you restart manager, it will still adhere to this value.
# stagger_minutes: The amount of minutes to wait before the next plot for this job can get kicked off. You can even set this to
# zero if you want your plots to get kicked off immediately when the concurrent limits allow for it.
# max_for_phase_1: The maximum number of plots on phase 1 for this job.
# concurrency_start_early_phase: The phase in which you want to start a plot early. It is recommended to use 4 for
# this field.
# concurrency_start_early_phase_delay: The maximum number of minutes to wait before a new plot gets kicked off when
# the start early phase has been detected.
# temporary2_destination_sync: This field will always submit the destination directory as the temporary2 directory.
# These two directories will be in sync so that they will always be submitted as the
# same value.
# exclude_final_directory: Whether to skip adding `destination_directory` to harvester for farming
# skip_full_destinations: When this is enabled it will calculate the sizes of all running plots and the future plot
# to determine if there is enough space left on the drive to start a job. If there is not,
# it will skip the destination and move onto the next one. Once all are full, it will
# disable the job.
# unix_process_priority: UNIX Only. This is the priority that plots will be given when they are spawned. UNIX values
# must be between -20 and 19. The higher the value, the lower the priority of the process.
# windows_process_priority: Windows Only. This is the priority that plots will be given when they are spawned.
# Windows values vary and should be set to one of the following values:
# - 16384 (BELOW_NORMAL_PRIORITY_CLASS)
# - 32 (NORMAL_PRIORITY_CLASS)
# - 32768 (ABOVE_NORMAL_PRIORITY_CLASS)
# - 128 (HIGH_PRIORITY_CLASS)
# - 256 (REALTIME_PRIORITY_CLASS)
# enable_cpu_affinity: Enable or disable cpu affinity for plot processes. Systems that plot and harvest may see
# improved harvester or node performance when excluding one or two threads for plotting process.
# cpu_affinity: List of cpu (or threads) to allocate for plot processes. The default example assumes you have
# a hyper-threaded 4 core CPU (8 logical cores). This config will restrict plot processes to use
# logical cores 0-5, leaving logical cores 6 and 7 for other processes (6 restricted, 2 free).
- name: mp600_1
max_plots: 999
farmer_public_key:
pool_public_key:
temporary_directory: /media/lionethan/chia_temp
temporary2_directory:
destination_directory:
- /media/lionethan/chia_final
size: 32
bitfield: true
threads: 2
buckets: 128
memory_buffer: 4000
max_concurrent: 7
max_concurrent_with_start_early: 8
initial_delay_minutes: 0
stagger_minutes: 60
max_for_phase_1: 2
concurrency_start_early_phase: 4
concurrency_start_early_phase_delay: 0
temporary2_destination_sync: false
exclude_final_directory: false
skip_full_destinations: true
unix_process_priority: 10
windows_process_priority: 32
enable_cpu_affinity: false
cpu_affinity: [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 ]
- name: mp600_2
max_plots: 999
farmer_public_key:
pool_public_key:
temporary_directory: /media/lionethan/chia_temp1
temporary2_directory:
destination_directory:
- /media/lionethan/chia_final
size: 32
bitfield: true
threads: 2
buckets: 128
memory_buffer: 4000
max_concurrent: 7
max_concurrent_with_start_early: 8
initial_delay_minutes: 0
stagger_minutes: 60
max_for_phase_1: 2
concurrency_start_early_phase: 4
concurrency_start_early_phase_delay: 0
temporary2_destination_sync: false
exclude_final_directory: false
skip_full_destinations: true
unix_process_priority: 10
windows_process_priority: 32
enable_cpu_affinity: false
cpu_affinity: [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 ]







![[對話式AI-3] Chatbot的記憶與決策–對話管理篇](https://www.lionethan.com/wp-content/uploads/2020/03/chatbot-blog-banner-aug-14-2018-825x510.png)
![[對話式AI-2] Chatbot的閱讀能力–自然語言理解篇](https://www.lionethan.com/wp-content/uploads/2020/02/1_RD1s9xBIvd_ycJUnX12Tyw@2x-825x510.png)